Failure Happens – Site Reliability Engineering (SRE)
Mistakes are proof that you are trying.
Site Reliability Engineering (SRE) helps further the evolution of the DevOps unification. DevOps is a concept describing the goal of uniting the traditional silos between software development and operation teams. An oversimplification of the caricature between these two cultures describes Dev as a fast moving, innovative, fix-later profit center focusing on applications and how they work. Ops is described as slow moving and risk-averse cost center focusing on applications and how they run. Bridging the cultural divide between these two teams allows for tighter collaboration on the same applications thereby reducing the time and friction necessary to develop new versions of software. During proper execution, a DevOps model leads to shorter development cycles – saving time and money (keeping layer 9 happy).
Reliability, of course, addresses a key requirement of maintaining system uptime and availability for users to access needed resources. Oxford defines reliability as “the quality of being trustworthy or performing consistently well”. Reliability engineering is a sub-discipline of systems engineering emphasizing the ability of equipment to function without failure. In software engineering, a system reliability of less than 100% is often acceptable. Outside of software engineering, is reliability less than 100% acceptable? What is the acceptable threshold in reliability for an airplane in the aviation industry or a power grid in the power system industry?
I have not failed. I’ve just found 10,000 ways that won’t work.
– Thomas A. Edison
With the significant risk in airplanes due to a potential mechanical failure while in the sky, commercial airplanes are designed with several backup systems in place. There is nothing in an airliner that is necessary to flight which is not at least triple redundant. The timing of some breakdowns can be unpredictable and unpreventable, such as lightning strikes, electromagnetic interference, fire, or explosions. Recently, headlines were made when the PW200 number two engine on United flight 328 carrying 231 passengers caught fire and burst into flames minutes after takeoff from DEN. Pilots spend hours in flight training simulators running through various failure scenarios. During training exercises, pilots cycle through “Non-Normal Checklists”, a subset of which includes “Fire is detected in the engine”. The pilots of United 328 followed this sequence before initiating overweight landing checklists (due to being full of fuel). Co-ordinating with air traffic control, pilots were able to safely land the UN328 on runway 26.

Engine #2 of UN328 on fire during flight
A comprehensive review of the checklist procedure and reaction of the pilots is described in the Youtube video below by Captain Joe. If a task is repeatable, it should be automated. Checklists like the one used by the pilots can be performed when failures are detected in an operations environment allowing for containment, isolation, and decommissioning. A core principle in SRE is a relentless focus on automation.
The only real mistake is the one from which we learn nothing.
– Henry Ford
Power grid systems have been in place for over 100 years. Most are now heavily regulated, which is a good thing. Regulations increase system reliability enhancements, putting into place lessons learned from previous failures and forcing system wide upgrades to be carried out unilaterally.
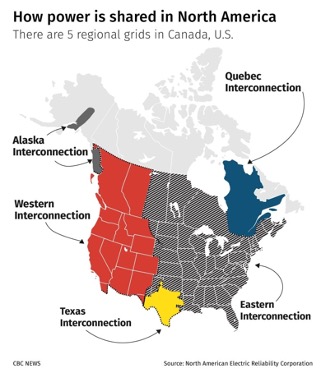
Another core concept in SRE is the idea that “failure is normal”. During the February 20th weekend, a significant portion of Texas lost power. Unfortunately, the timing of events created the perfect storm (no pun intended). There were many contributing factors, but two very direct causes were:
- A record demand for power to heat homes due to very unusual severe winter weather. In fact, Texas typically experiences much higher demand for power during the summer months due to use of air conditioning.
- Loss of power generation from plants not equipped to deal with extreme cold.
Gas supply lines and water intakes froze as they were exposed to the elements and rendered unable to feed the power plants. A previous extreme weather event in 2014 generated a report identifying these problems along with the recommended steps to mitigate this risk in the future. Why were these steps not taken? Well, the simple answer is upgrades take time and, more truthfully, upgrades cost money. If costly upgrades cannot be justified to ratepayers or investors, they simply don’t happen.
Strong regulation forces electrical grids to perform necessary upgrades based on lessons learned during postmortems of past failures. Regulation also defines a minimum state of compliance reducing the risk of interconnecting neighbouring grids creating larger regional grids. Multiple connections to other grids allow importing backup energy if local power generation can’t meet demand for whatever reason. While lessons learned from major events can be reviewed and analyzed, time to implement any changes limits the rate at which new features or suggested recommendations can be put into practice.
I’ve missed more than 9000 shots in my career. I’ve lost almost 300 games. Twenty-six times I’ve been trusted to take the game-winning shot and missed. I’ve failed over and over and over again in my life. And that is why I succeed.
– Michael Jordan
To put users at ease, systems would guarantee 100% reliability with 100% availability, however this is the wrong target. In SRE, an appropriate service level objective (SLO) is selected and agreed upon by the product and SRE team(s). There is an exponential increase in the cost of developing and maintaining a system as reliability approaches 100%. Another core concept in SRE is a reframing of “availability” in terms of what a business can tolerate.
SRE adopts a framework allowing software and applications to be continuously integrated (CI) and continuously deployed (CD) measured against SLOs. The SLO/SLI methodology removes the need to seek perfection in design in favour of building what is “good enough”. This allows rapid delivery of new products, features, and business value while continually improving on the benchmark of “good enough”. Using practical alerting, anomalies can be detected with effective baselining. Each incident undergoes a post-mortem within a culture that embraces “learning from failure” and strives to minimize barriers to implement radical change. Implementing these changes with the potential for failure allows developers to eventually succeed, knowing they may occasionally miss. SRE can handle overloads and address cascading failures, providing a safety net to detect and contain failures and, more importantly, learn from them.
Failure happens! It is always better to find mistakes early and before products or software go into production. The ability to detect failure measured in the context of an SLO allows reasonable decisions to be made, such as limiting the spread of a fire or slowing the pace of releases. Once the sources of the errors are determined, specific fixes can be tested and implemented. While learning from those failures is key, implementing those lessons learned in a timely fashion becomes critical to maintaining business values and sometimes preserving life.
Slàinte
References
https://www.poentetechnical.com/aircraft-engineer/airplane-redundancy-systems/
https://www.cbc.ca/news/technology/power-outages-texas-canada-1.5920833?cmp=rss
Further Reading